
大家好,我是阿超!今天要给大家介绍一个让我眼前一亮的AI工具——Cactus Compute。这可不是普通的AI工具,它是一个专门让AI模型在手机上本地运行的跨平台框架。简单来说,就是让你的手机变成一个"AI小电脑",不用联网就能跑各种AI模型!
什么是Cactus Compute?
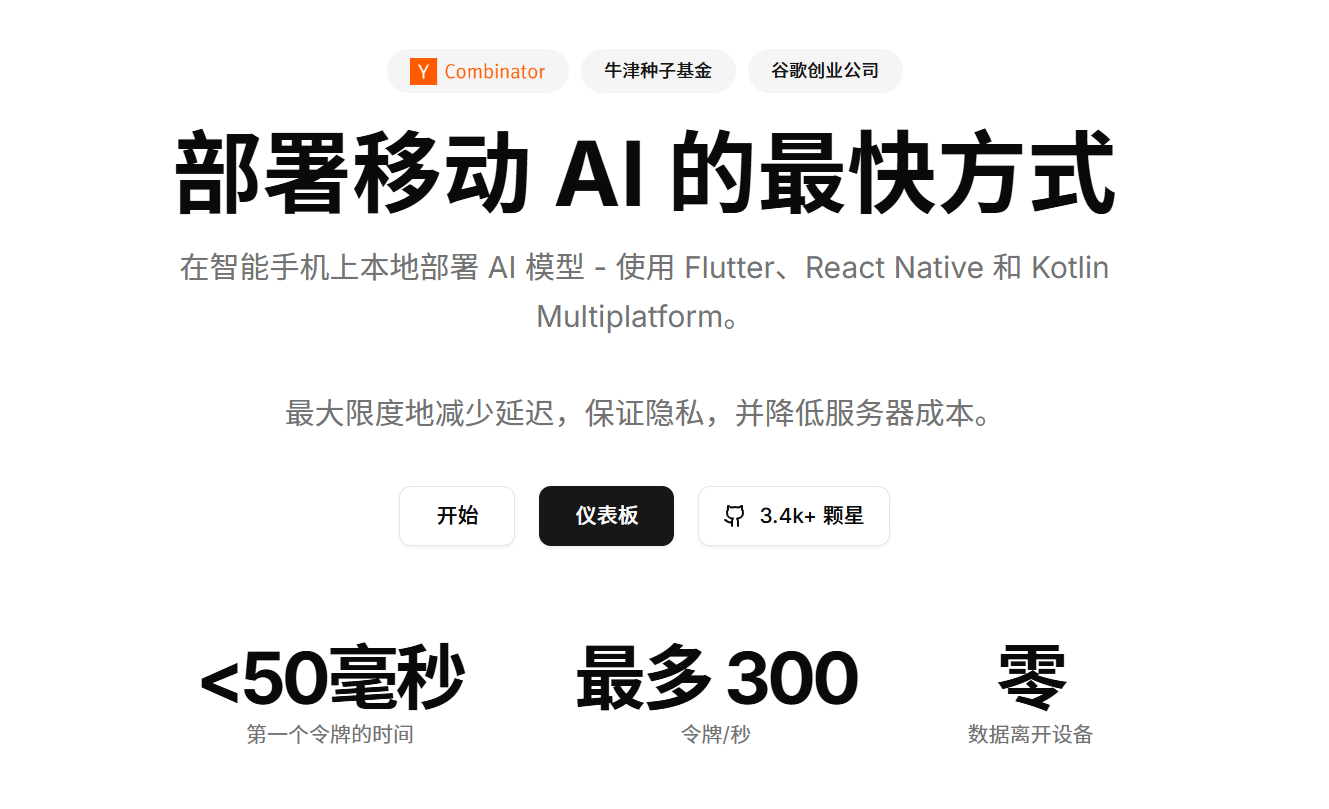
Cactus Compute 是一个专门为移动设备设计的AI部署框架,支持在Flutter、React Native和Kotlin Multiplatform等主流移动开发框架中使用。它的核心理念是"边缘计算"——把AI计算任务放在用户的手机上完成,而不是依赖云端服务器。
想象一下,你的手机APP可以像ChatGPT一样智能对话,但完全不需要联网,数据也不会离开你的设备,这听起来是不是很酷?
主要功能亮点
🚀 极速响应
- <50ms的首个token响应时间:几乎是瞬间就能开始生成内容
- 最高300 tokens/秒:在主流手机上都能流畅运行
- 零数据传输:所有计算都在设备上完成,保护用户隐私
📱 跨平台支持
Cactus Compute 支持三大主流移动开发框架:
- Flutter:Dart包直接集成
- React Native:NPM包轻松安装
- Kotlin Multiplatform:原生Kotlin支持
🛡️ 隐私保护
这是我个人最喜欢的一点!Cactus Compute 默认就是设备端推理,意味着:
- 你的对话记录、图片处理等数据完全不会上传到云端
- 适合处理敏感信息,比如医疗记录、财务数据等
- 符合GDPR等隐私法规要求
🌟 多模态能力
支持语言、视觉和语音模型,一个框架搞定多种AI任务:
- 语言模型:智能对话、文本生成
- 视觉模型:图像识别、图像生成
- 语音模型:语音识别、语音合成
🔄 云端备用
虽然主打本地运行,但Cactus Compute也提供了云端备用方案。对于需要大量计算或异步处理的任务,可以无缝切换到云端推理。
性能表现如何?
根据官方基准测试,在主流设备上的表现相当不错:
在iPhone 16 Pro Max上:
- Gemma3 1B Q4模型:54 tokens/秒
- Qwen3 4B Q4模型:18 tokens/秒
在三星Galaxy S24 Ultra上:
- Gemma3 1B Q4模型:42 tokens/秒
- Qwen3 4B Q4模型:14 tokens/秒
这个速度对于日常使用来说完全够用,聊天、问答都能流畅进行。
适合哪些人群使用?
👨💻 移动应用开发者
如果你正在开发需要AI功能的移动应用,Cactus Compute绝对是你的好帮手。它大大降低了集成AI功能的门槛。
🔒 注重隐私的用户
对于处理敏感数据的应用(如医疗、金融、企业应用),本地AI推理能提供最高级别的隐私保护。
🌐 网络环境差的地区
在信号不好或网络受限的地区,本地AI模型能确保应用功能正常运行。
💰 想要降低服务器成本的企业
把AI计算任务分散到用户设备上,能显著降低云端服务器的运营成本。
阿超的使用体验
作为一个经常测试各种AI工具的人,我觉得Cactus Compute最大的优势在于它的实用性。很多AI工具虽然功能强大,但要么需要联网,要么对设备要求很高。而Cactus Compute让普通手机也能跑AI模型,这真的很接地气。
而且它的集成过程相对简单,文档也比较完善,对于有一定开发经验的人来说上手很快。
总结
Cactus Compute 代表了移动AI发展的一个重要方向——边缘AI计算。它解决了传统云端AI的几个痛点:延迟、隐私、成本和网络依赖。
优点总结:
- ✅ 极低的延迟和良好的性能
- ✅ 强大的隐私保护
- ✅ 跨平台兼容性好
- ✅ 支持多模态模型
- ✅ 降低服务器成本
需要注意的地方:
- ⚠️ 模型大小受限于设备存储
- ⚠️ 复杂模型在低端设备上可能性能有限
- ⚠️ 需要一定的开发经验来集成
总的来说,如果你正在寻找一个能在移动设备上本地运行AI的解决方案,Cactus Compute绝对值得一试。它让AI真正"飞入寻常百姓家",让每个人都能在手机上体验到AI的便利。
